第5回の教材 (1) データ活用の流れ
データ活用の流れ
ビッグデータに限らず、データを活用する手順は次のとおりです:- データの収集・蓄積
- データの前処理
- データの分析
- データの可視化
- データの利活用
収集するデータの形態
- 構造化データ
- コンピュータで処理しやすいような構造を持っているデータ
- Excel ドキュメント、データベース etc.
- 半構造化データ
- 構造化はされていないが、要素に「タグ付け」などの意味合いが持たされているデータ
- xml ( Extensible Markup Language ), json ( JavaScript Object Notation ) etc.
- 非構造化データ
- データ内に規則性の無いデータ
- Word ドキュメント, pdf, 音声ファイル, 画像ファイル, SNS のコンテンツ etc.
- 時系列データ
- 時間の経過に伴って観測されるデータ
- 気象データ, 株価, 感染者数 etc.
データの前処理
蓄積されたデータを分析プログラムに入力するために前処理を行います。- データクレンジング(データクリーニング)
- データのエラーやノイズ、欠損値等を修正する作業
- データの統合
- さまざまなデータソースから収集されたデータを統合する作業
- データの変換
- 分析プログラムの指定するフォーマットに変換す作業る
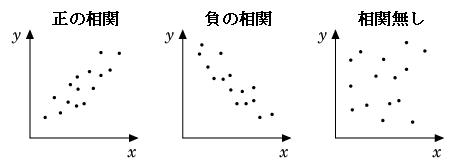
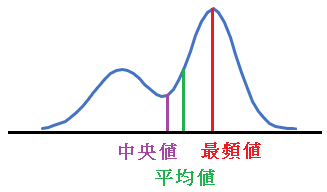
データの可視化
例えばオーソドックスな統計処理では次のような値でデータの特徴を表します:
|
|